| images | ||
| src/feather | ||
| .dockerignore | ||
| .gitignore | ||
| .python-version | ||
| Dockerfile | ||
| LICENSE | ||
| pyproject.toml | ||
| README.md | ||
| uv.lock | ||
Feather: file-based RSS reader client
Feather is a RSS reader client. It can:
- connect to any server supporting the Tiny Tiny RSS API or the Google Reader API (FreshRSS, Miniflux, many others) :D
- read your feeds in a native interface, regardless of desktop environment, CLI or GUI :D
- read your feeds fully offline :D
- integrate with many other programs effortlessly :D
- and do all that while using less resources than a web browser showing a blank page :D
That's right, using an innovative technology known as "plain files", Feather allows you to read your feeds in any file manager that exist or will exist in the future.
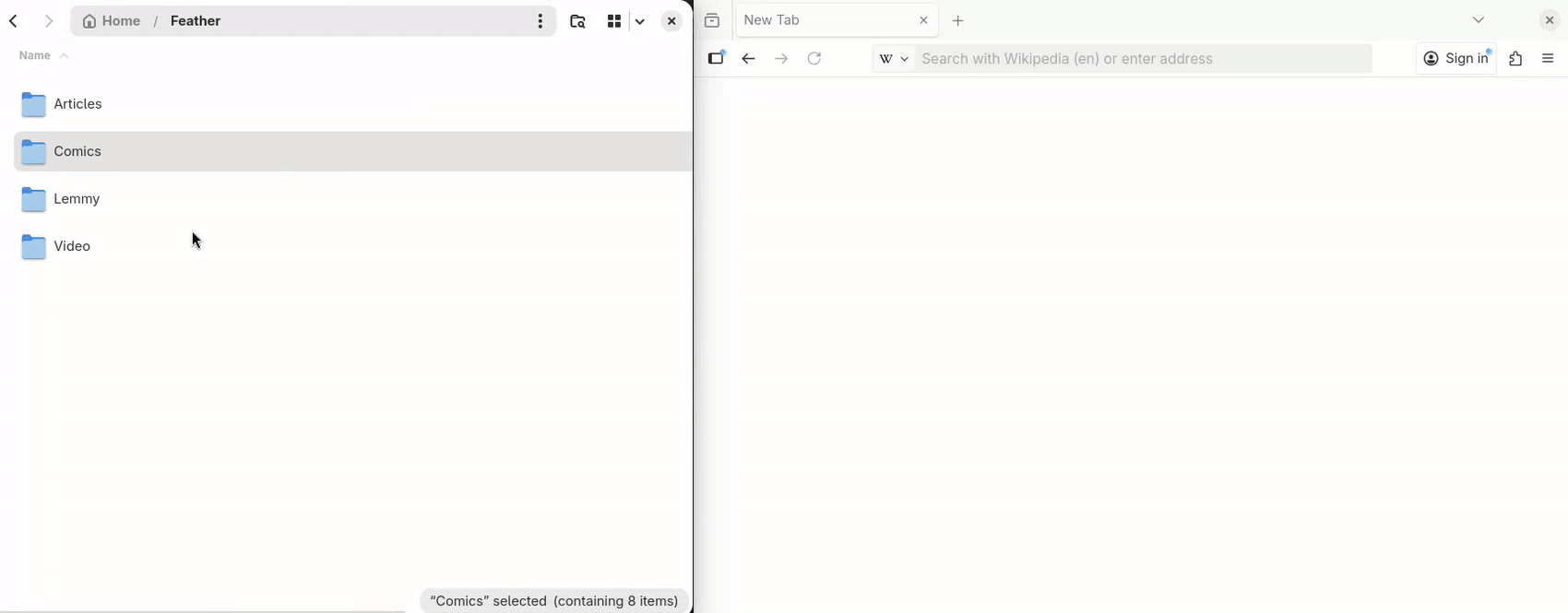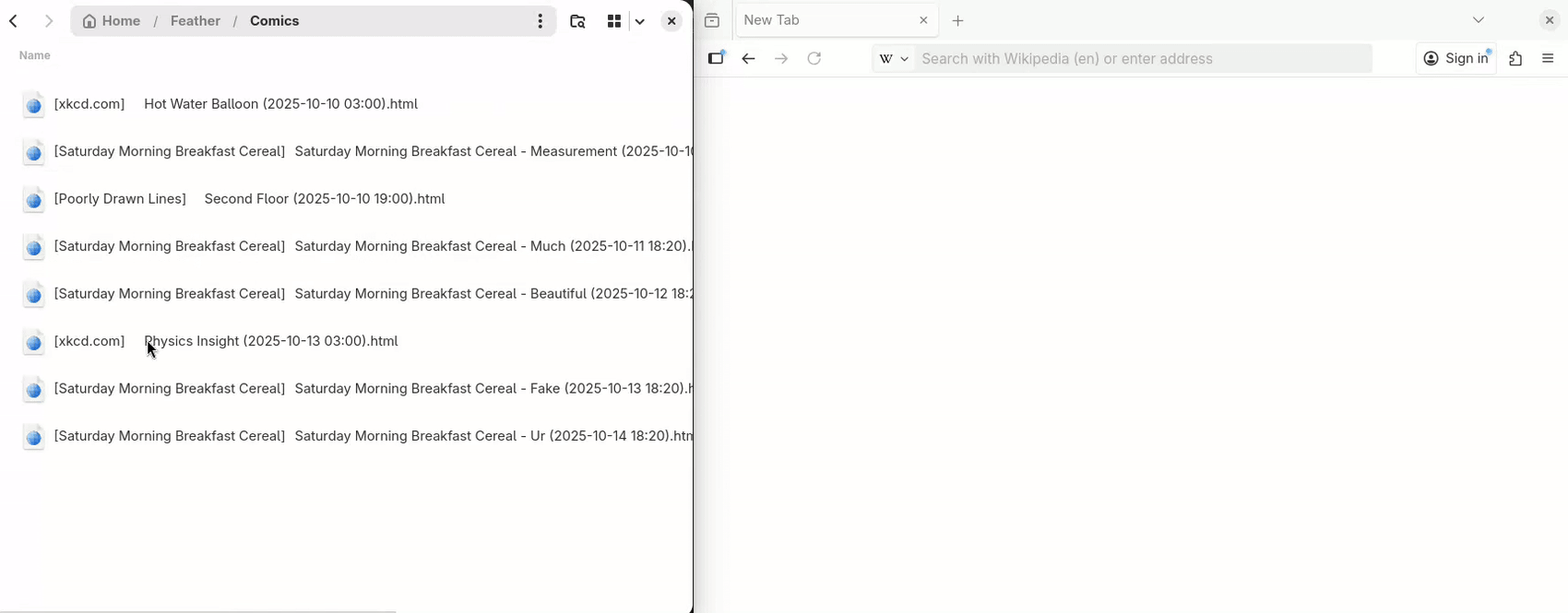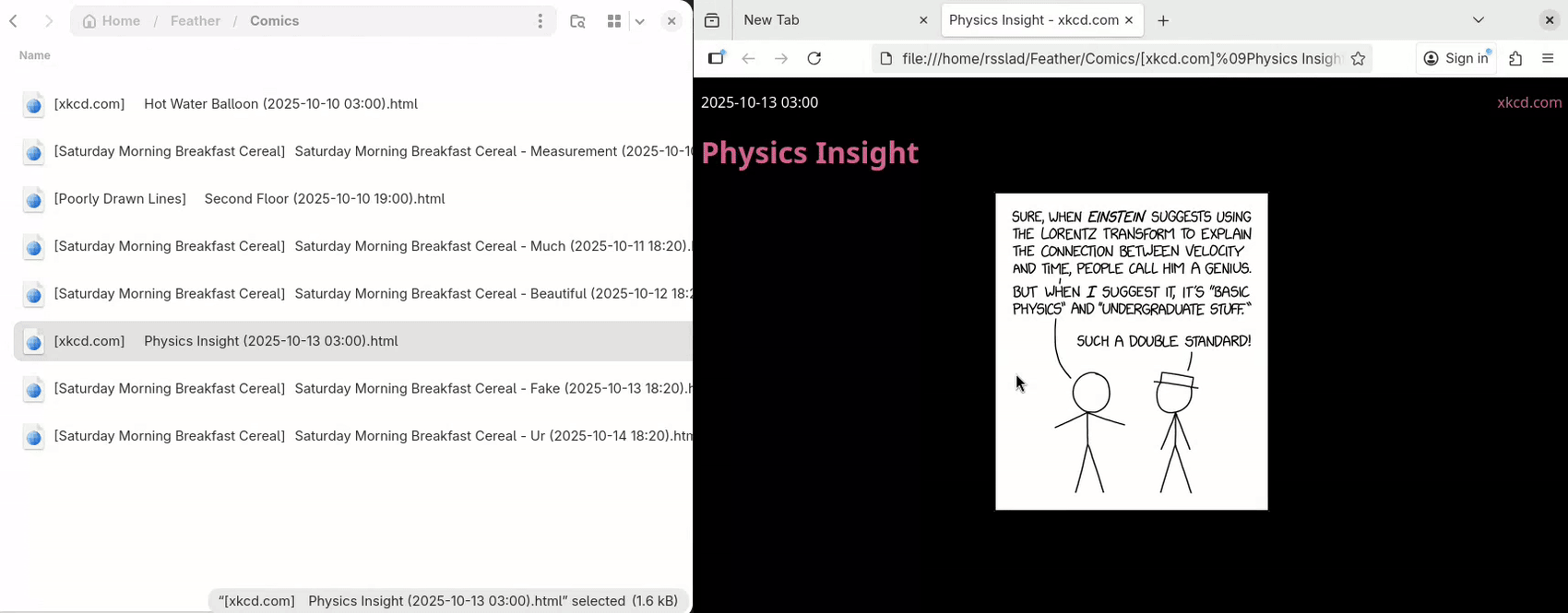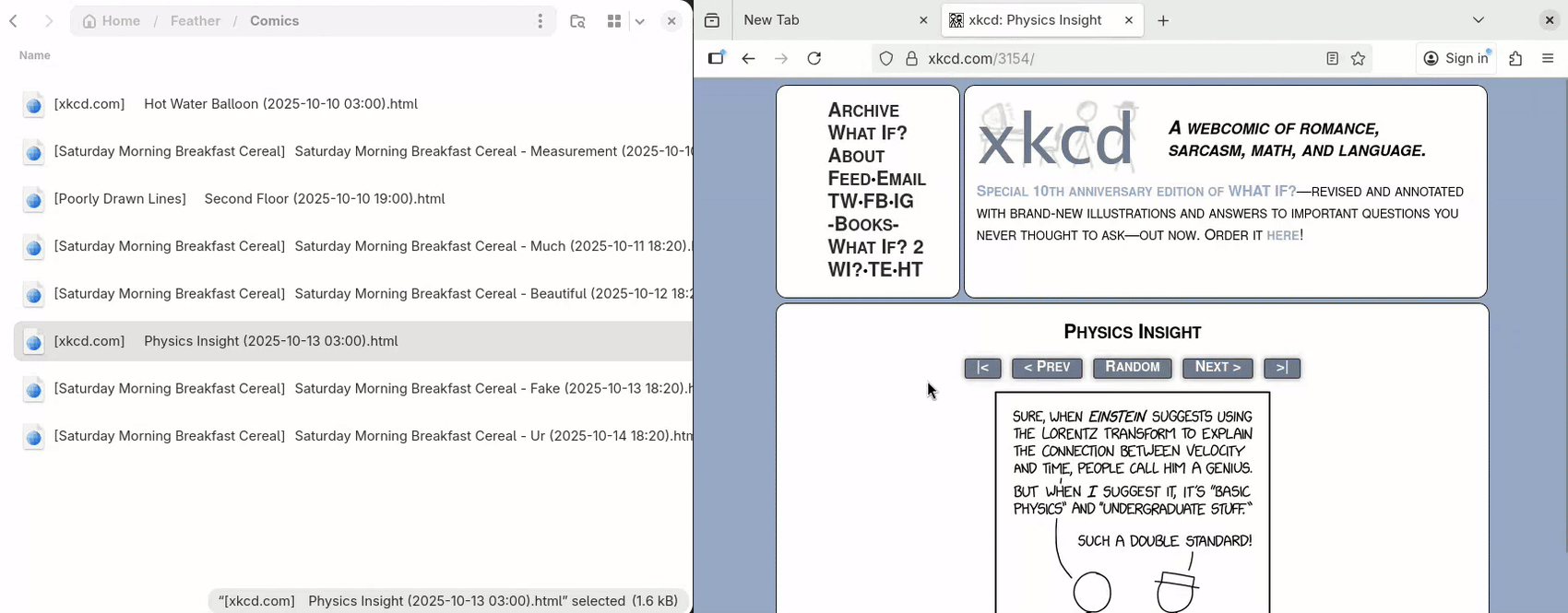
Note however that Feather is meant to be used alongside a RSS reader server, meaning:
- no grabbing feeds on its own, requiring a server to connect to :(
- no feed management interface; Feather only support reading articles and marking them as read/unread :(
Usage
All demonstrations are done under Linux with GNOME Files, but a file manager is a file manager, use what you fancy.
Navigating feeds a.k.a. "using a file manager"
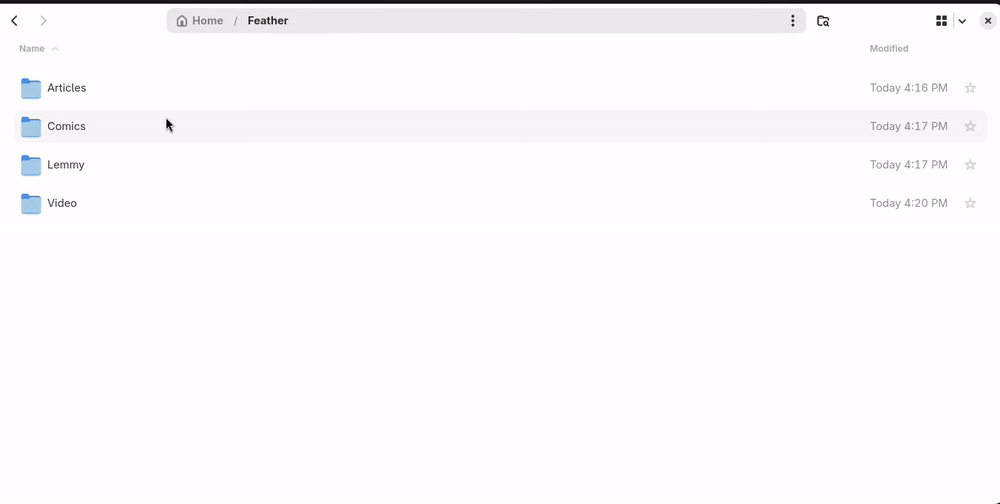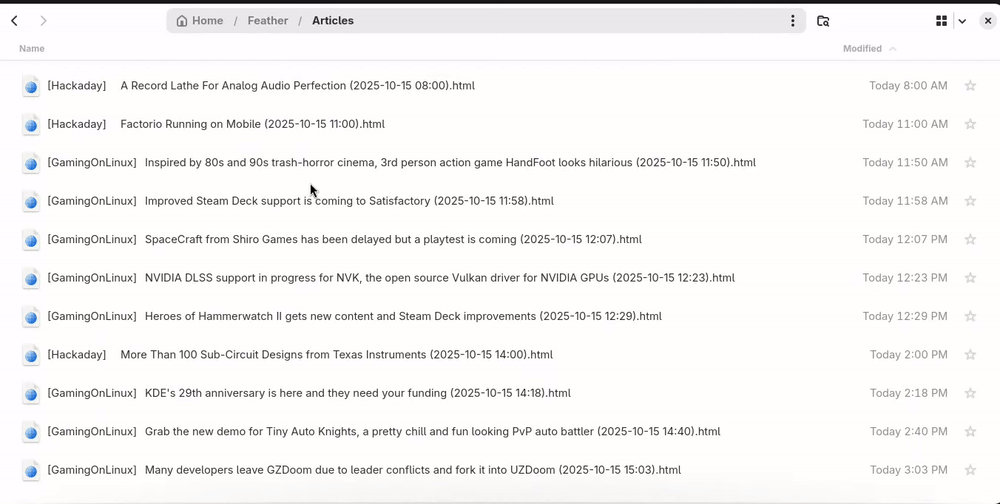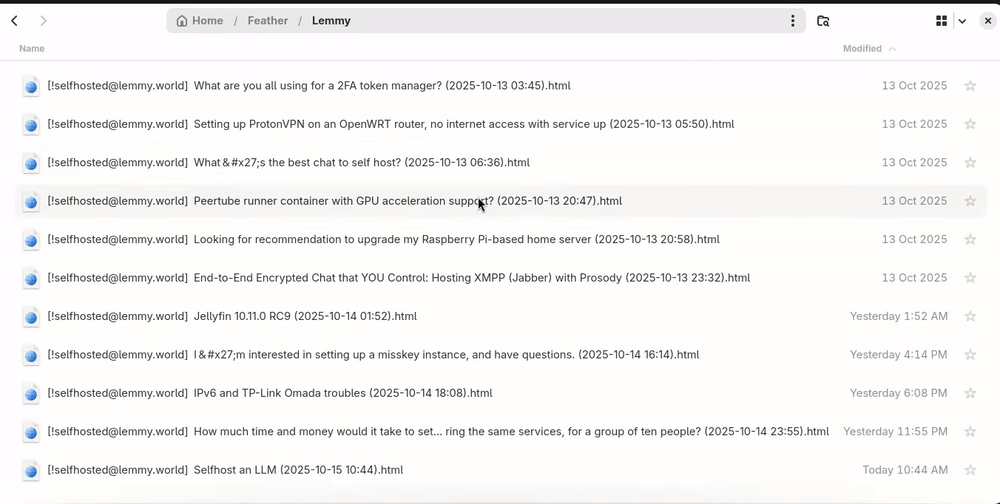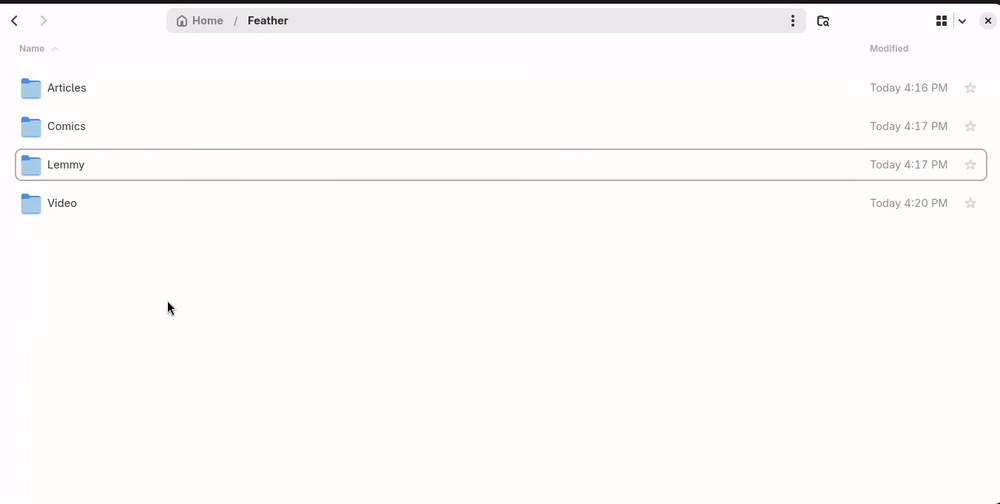
Navigating articles
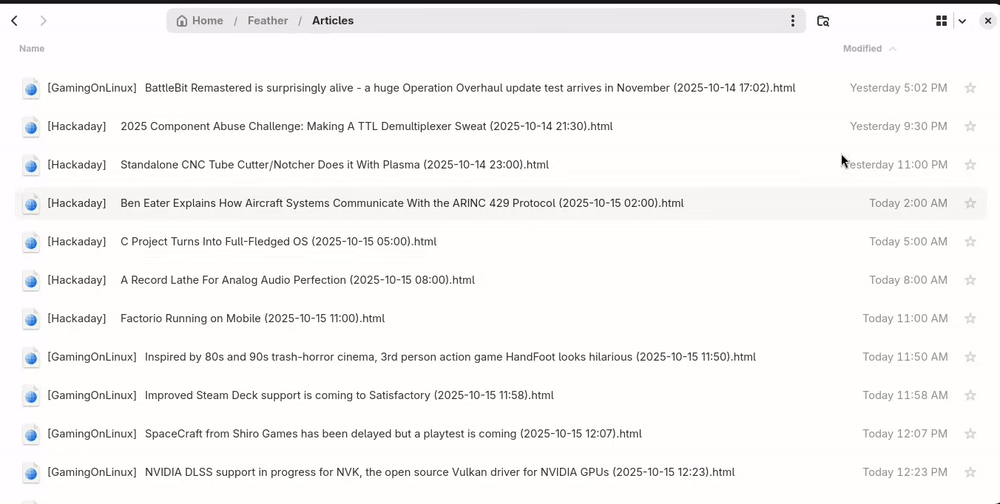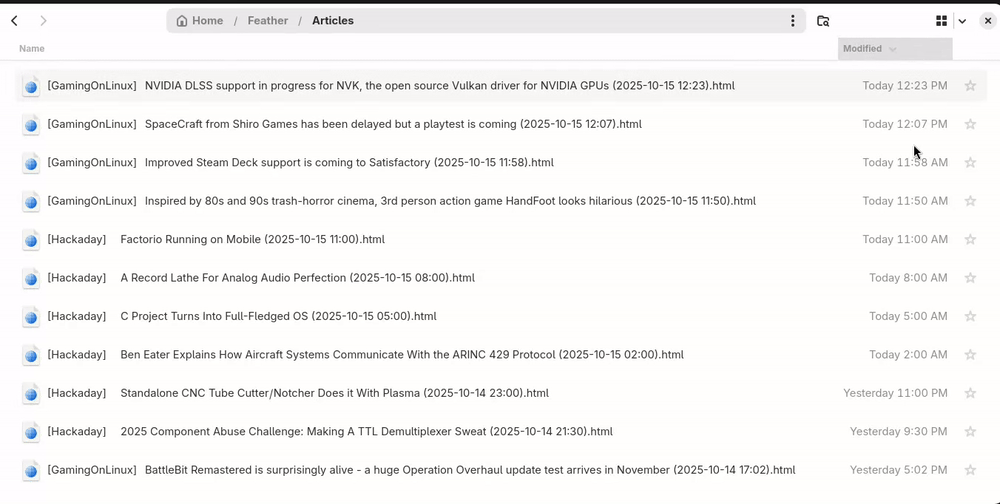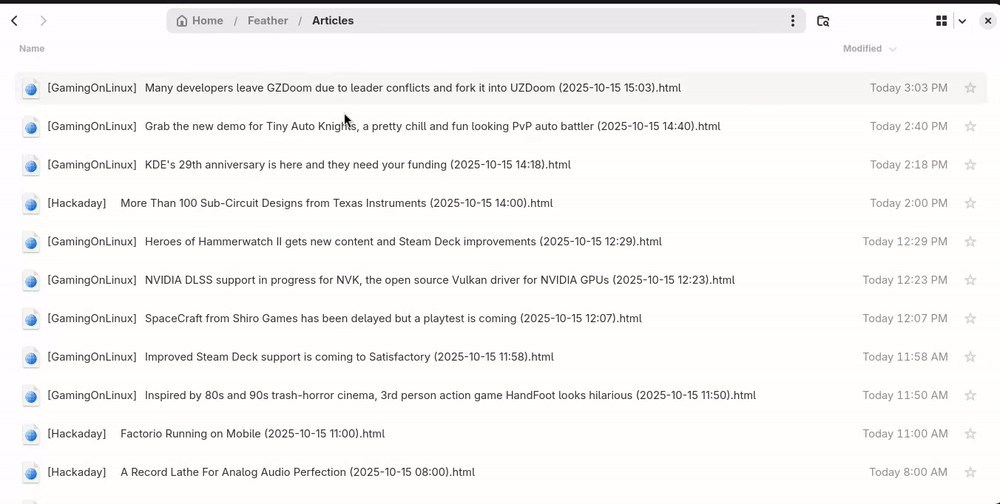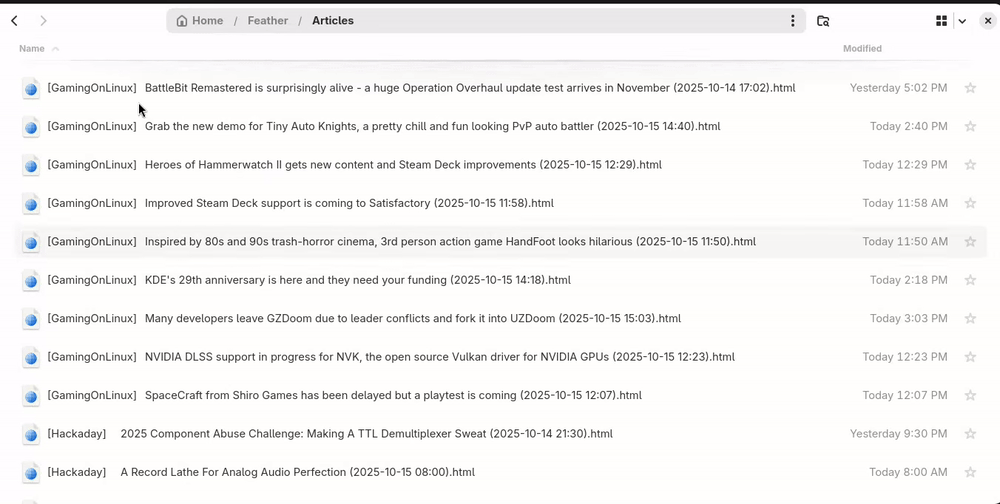
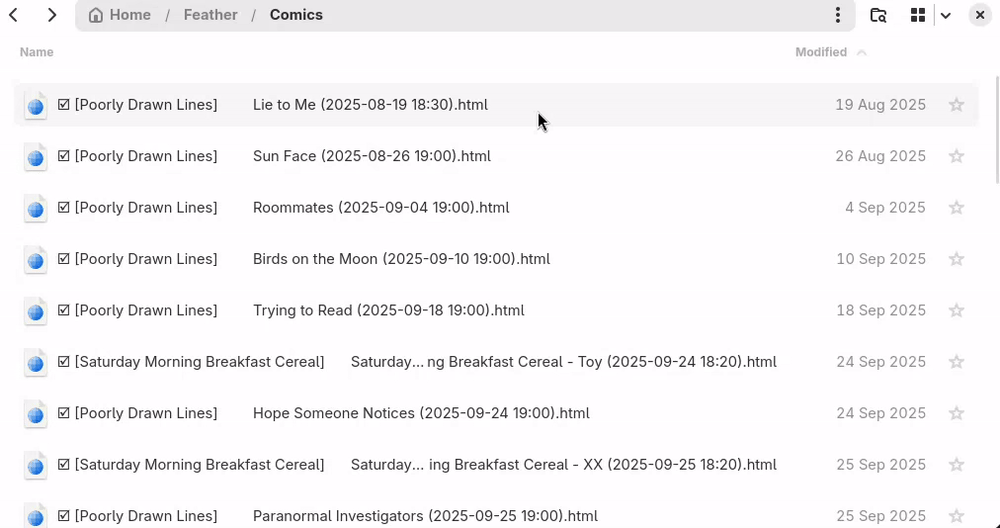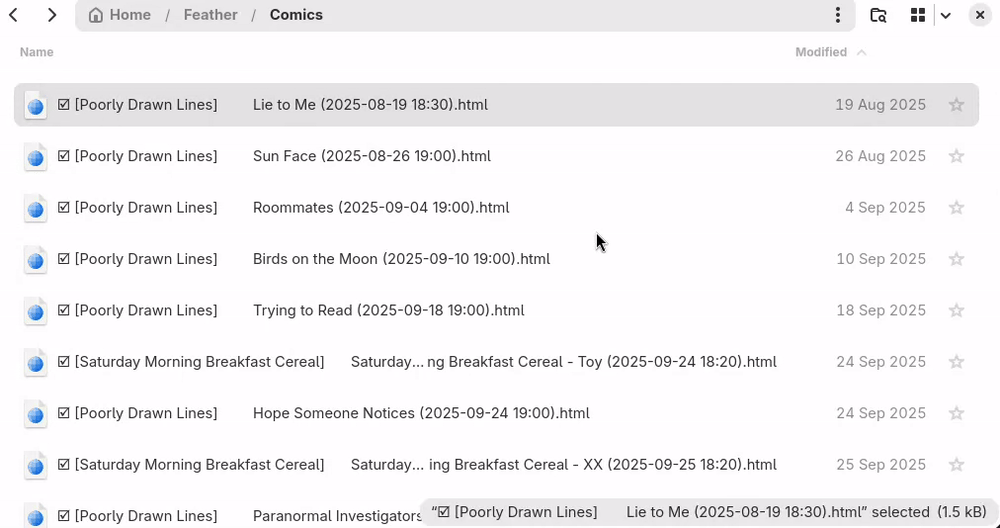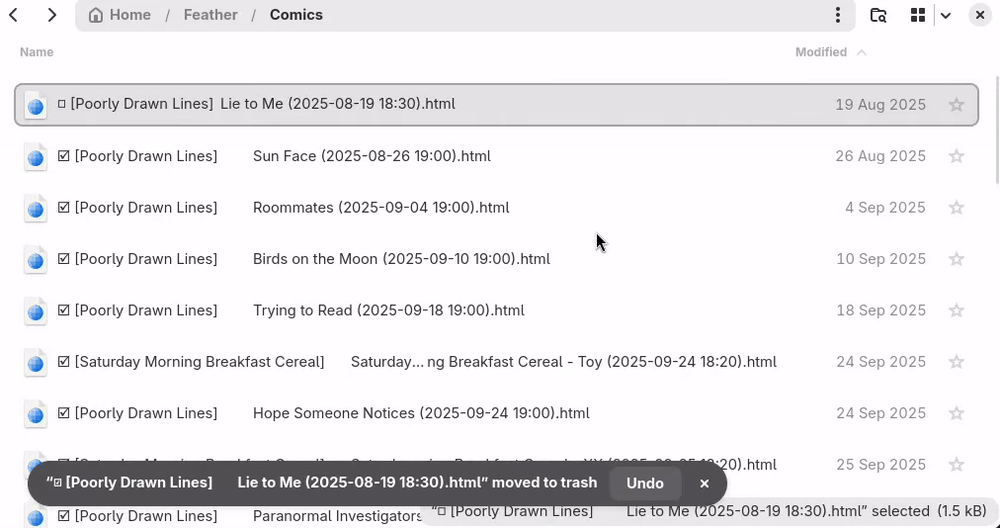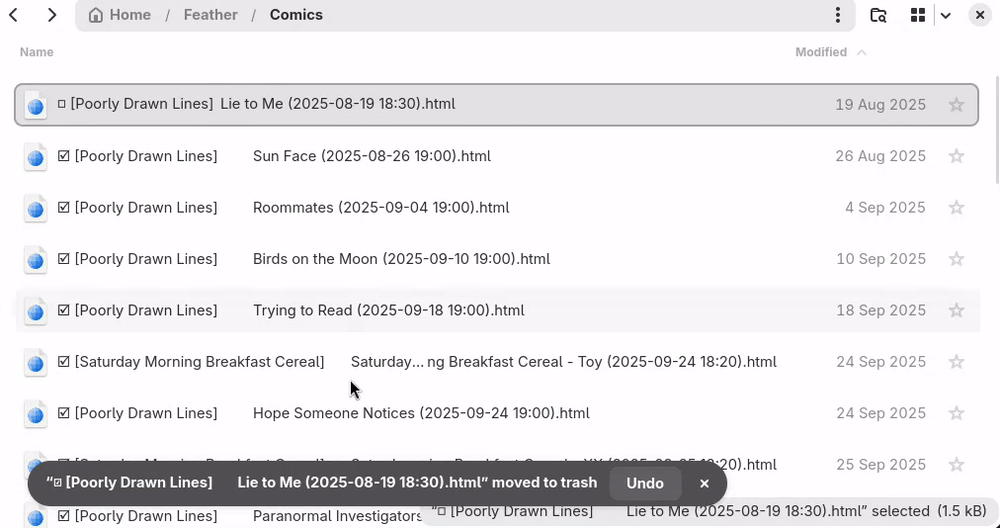
Feed categories are directories, and each file in these directories is an article.
Sorting articles
An article file's modification time is the article publication time; you can sort by publication date by sorting the files by modification time, or sort by feed by sorting by filename.
Searching
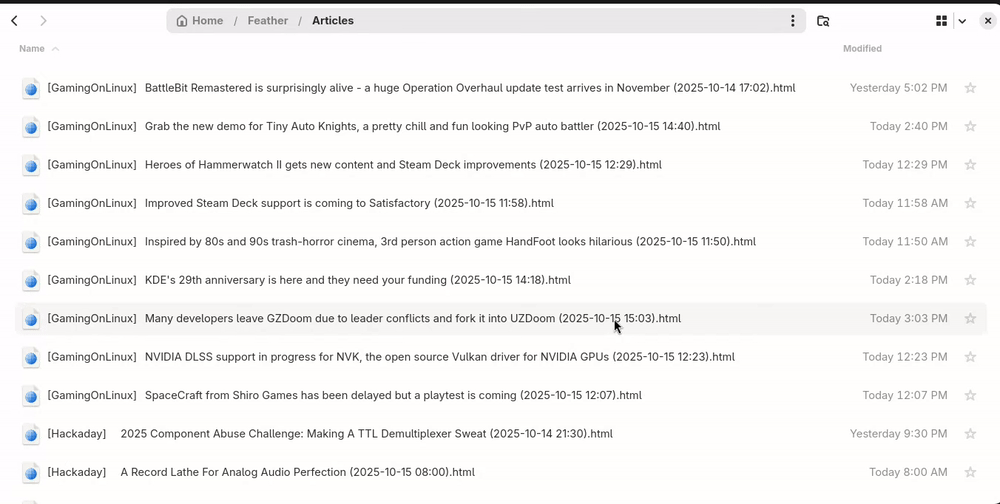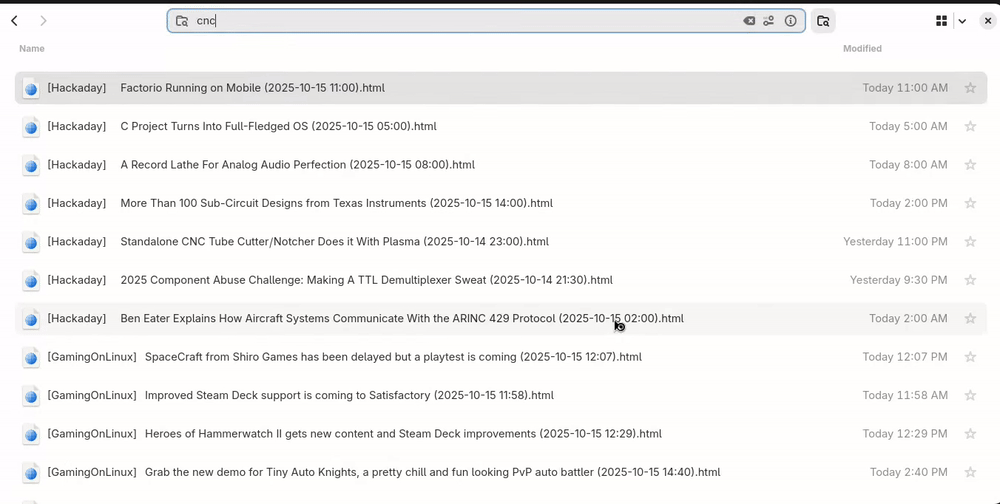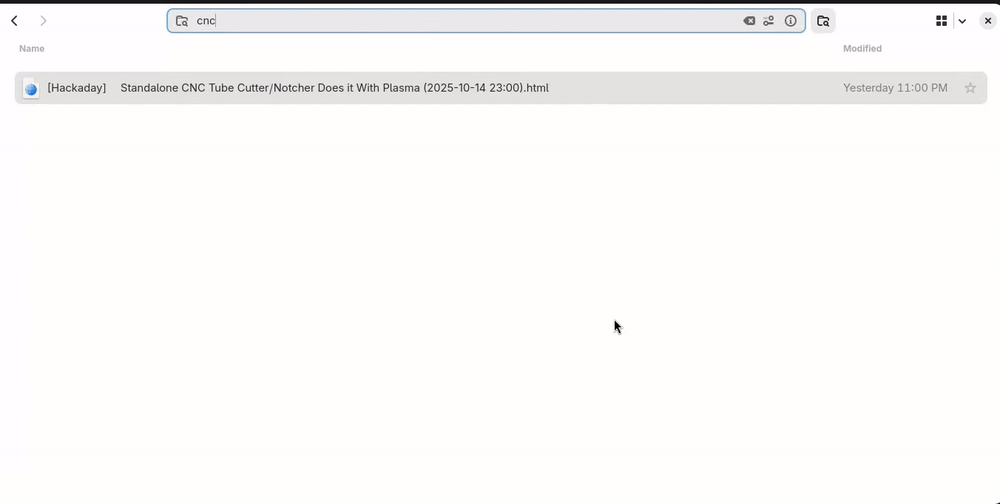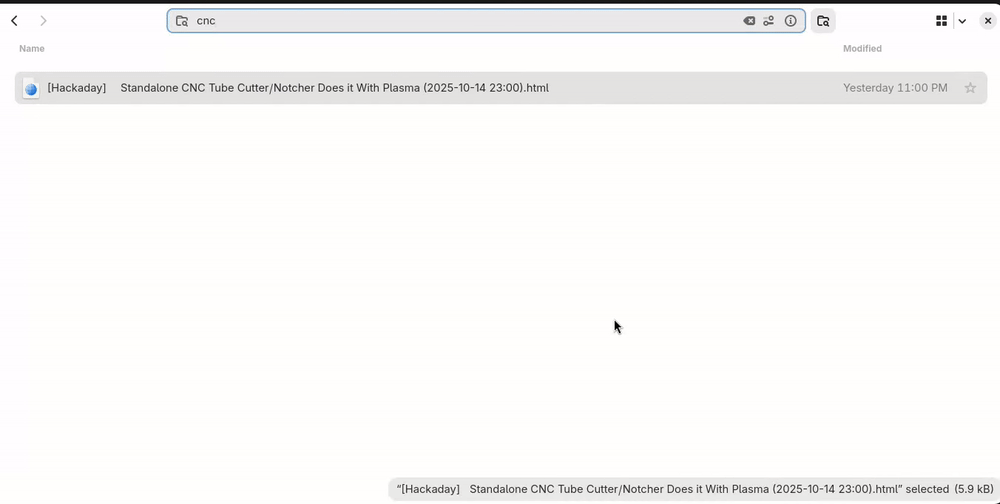
Tip: if you have nested categories, search "html" to list all the articles in the category and its sub-categories in the same view.
Marking articles as read
Deleting an article will toggle their read status (will take effect on the next synchronization to the server).

Handling read articles
Surprisingly, the read articles can be found in the trash. If you restore them before the next synchronization, it's be as if nothing happened. However, restoring the file after synchronization will not work if you want to mark the article as unread.
Instead, if you want Feather to also track read articles, you could add to your configuration file:
# Grab both read and unread articles into the local directory
server.only_sync_unread_articles = false
# Add a checkmark in the article filename indicating the read status
html.filename_template = "{% if unread %}☐{% else %}☑{% endif %} [{{ feed_title }}]\t{{ title }} ({{ published }}).html"
Now both read and unread articles will be stored in the Feather reader directory, and if you delete a read article file, the article will be marked as unread and the file will be recreated during the next synchronization.
Updating with the server
Run feather sync to synchronize all local data with the server. The synchronization is done in two parts:
feather sync-upwhich upload local changes to the server (e.g. update read status of local articles);feather sync-downwhich download all articles from the server into the local state. This might be a lot of data depending on how many articles you have on the server.
If you don't want to bother running feather sync manually, you can also start the Feather update daemon using feather daemon. The daemon will periodically call sync-up and sync-down for as long as it runs.
If you are offline
Nothing change, but all the synchronization commands will wait until the server become reachable again.
Configuration
Feather will try to load the configuration from the file config.toml by default. A lot of things can be configured, see the default configuration file for details. Most configuration options can also be set using environment variables - this is also detailed in the default configuration file (here's another link if your mouse is too far from the previous one).
If you already have local data but have changed configuration that affect how files are generated (like the HTML or filename templates), you can call feather regenerate to regenerate all local files with the new configuration.
If you changed to another remote server or if you somehow messed up your local files, you can also call feather clear-data to nuke all local data, likely followed by a full synchronization using feather sync.
Layer other things on top
Since, as the kids say, everything is a file, Feather can be easily integrated with any other program which operate on files (and there's a lot of those). A couple examples:
- you can use Syncthing to synchronize the reader directory with other computer without having to install Feather on each one. You'd still have to install Syncthing on each one, but if for some unknown reason you prefer installing Syncthing to Feather, it works. Note that Syncthing real-time change detection can sometime miss changes when there's a lot of small files like with Feather, so you may want to reduce the Full Rescan Interval in the share settings unless you're fine with some of your feeds taking a whole hour to update;
- you can process your feeds easily with regular scripts:
find reader/ -iname 'trump' -deletewill mark all feeds containing "Trump" in their filename as read; which I think is easier than messing around with your feed reader API or convoluted filtering rules directly, but that's just my opinion.
Installation
Docker
If use Docker or Podman, an image is available at codeberg.org/reuh/feather:latest.
For example, to start a new container with the Feather daemon running, using the config.yml (see basic configuration) in the current directory and exposing the feeds in the reader directory:
docker run -d -v ./config.toml:/feather/config.toml:ro -v ./reader:/feather/reader -v feather-data:/feather/data --name feather codeberg.org/reuh/feather:latest daemon
Instead of using a configuration file, you may also use environment variables; see the default configuration file for details.
If you need to run Feather commands in a running container, run for example docker exec feather feather regenerate. Otherwise you could also start a new container as described above but using a command other than daemon.
If you're wondering how monstrous the resources required by Feather are, with my ~600 feeds on my Tiny Tiny RSS, Feather stays at ~50MB RAM usage and take ~4KB of disk space per article. The docker image is ~120MB, which does not fit on a floppy disk but does easily on a CD.
Quadlet
If you're using Podman on Linux/systemd with Quadlet to manage your containers, here's an example Quadlet user file you can put in ~/.config/containers/systemd/feather.quadlet:
[Unit]
Description=Feather container
[Container]
ContainerName=feather
Image=codeberg.org/reuh/feather:latest
Exec=daemon
# Auto-update container
AutoUpdate=registry
# Configuration file
Volume=%h/Feather/config.toml:/feather/config.toml:ro,Z
# Reader/article directory
Volume=%h/Feather:/feather/reader:z
# Feather data volume
Volume=feather-data:/feather/data
[Service]
Restart=on-failure
TimeoutStartSec=300
[Install]
WantedBy=default.target
Kindly ask systemd to reload unit files, start Feather, done:
systemctl --user daemon-reload
systemctl --user start feather
Raw
Feather should be able to run on anything that can run Python 3.12 or newer (you might need to change html.max_filename_length and html.filename_replacement in the configuration if your filesystem has exotic limitations).
Once you have Python installed, download this repository and pip it up by running pip install inside it. You should be able to run feather sync or whatever command you want to run according to the usage chapter. Although I personally use uv, so I'd just run uv sync and then uv run feather sync to run Feather.
Basic configuration
In order for Feather to be able to do something useful, it needs to be able to connect to your RSS reader server. Here's some basic config.toml configuration files depending on what API you use:
Tiny Tiny RSS
[server]
api = "ttrss"
url = "https://ttrss.example.com" # Tiny Tiny RSS URL
user = "rsslad" # RSS reader username
password = "hunter2" # RSS reader password/application password
[datetime]
timezone = "Europe/Bucharest" # set your local timezone
Google Reader API (FreshRSS, Miniflux, and others)
[server]
api = "googlereader"
url = "https://freshrss.example.com/api/greader.php" # API endpoint URL
user = "rsslad" # RSS reader username
password = "hunter2" # RSS reader password/application password
[datetime]
timezone = "Europe/Bucharest" # set your local timezone
There's more you can change in the configuration file, see the default configuration file and the configuration chapter for details.
FAQ
I mean nobody asked them yet but I think I have a pretty good grasp on what people what to know.
Why?
I rely on RSS a lot to keep in touch with outside my room, and I've been using Tiny Tiny RSS to do that for years at this point. Unfortunately, the historical developer decided to stop development this October 2025, and after trying other RSS readers I was unsatisfied and decided to make my own. As I was contemplating how to design the RSS reader of my dreams, I had a epiphany: a RSS reader is nothing more than directories and files. This was great because it meant I didn't have to make a GUI, as like most people, I find working more than necessary generally unpleasant. But then, it turned out that as far as personal effort go, something even better happened: the Tiny Tiny RSS community is continuing its development. Relieved but at the same time dejected that my epiphany went to waste, I thus decided to make only the directories and files part of my RSS reader, and let Tiny Tiny RSS do the rest. And here we are.
Why the name "feather"?
My mom taught me that if all my friends jump off a bridge I should too, and since most popular open-source projects are named after a common English noun I decided to do the same. If you're looking for a set of icons, a JavaScript framework, ML libraries, data analytics libraries, a game server, a smartphone application, or a lot of other things that aren't a RSS reader client, I regret to inform you that you have unfortunately found the wrong Feather.
What should I eat tonight?
Spaghetti alla carbonara is often a safe choice; even if you substitutes all of the ingredients you'll likely still end up with something decent. It still counts as carbonara if you use cream and mushrooms, trust me, I know how to say hello in Italian.
Future improvements
While I mostly started this project for fun, it ended up actually quite usable, so I'm at least going to maintain it. As for new features, unless an incredible idea comes I'd like to keep this project simple (try your luck in the issue tracker!). But still, here's still some things that I wrote down during development that may be done at some point:
- Store & expose article attachments in the templates
- Partial synchronization (using since_id for ttrss (article updates?) and start_time for googlereader)
- Think of a third one, two is a bit sad
TODO before publishing
- Write documentation
- Re-read
- Tag v1.0 in git & container
- Publish